av Lillian
Brevik

Artificial Intelligence, AI är en gren inom datavenskap som handlar om datorers förmåga att simulera intelligent beteende.
Egenskaper som är karakteristiska för AI:
Autonomi
Förmåga att uträtta uppgifter i komplexa miljöer utan ständig styrning av användaren.
Adaptivitet
Kapaciteten att förbättra sin prestationsförmåga genom att lära sig av erfarenheter
Machine Learning, ML är en teknik inom AI där en dator kan lära sig genom en mängd data utan att ha tilldelats en komplett uppsättning regler.
Deep Learning, DL är en teknik inom ML för att utföra inlärning baserat på hur våra hjärnors eget nätverk av neuroner fungerar.
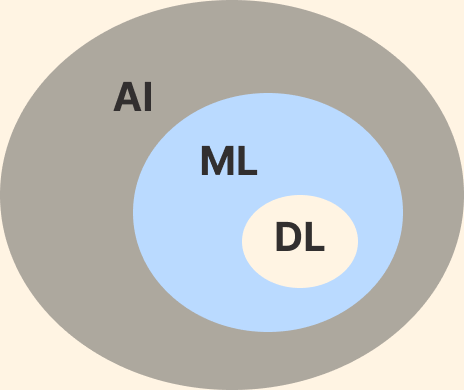
Den del av AI som jag kommer att fokusera på här är Machine Learning.
Mycket av det jag går igenom här har avancerade algorithmer och matematiska förklaringar men jag väljer att hålla saker på en nivå
där man kan förstå lite om "hur" det fungerar. Det finns många maskininlärningsbibliotek,
såsom TensorFlow, Keras, Pandas med flera, som programmerare kan använda för att slippa skriva hela koden själv.
Jag har lagt in länkar till program jag gjort i p5.js och den som vill får gärna kopiera dem och leka vidare med dem.
Min största inspirationskälla till mitt arbete med ML är Daniel Shiffman på The Coding Train
Om du vill lära mer om p5.js och ML så kolla noga på koden i de program jag länkat till. Kommentera bort delar (i JavaScript genom att sätta // framför raden) och se vad som då händer.
Du kan också skriva "console.log( 'vad du nu vill kolla'')" lite här och där i koden för att försöka förstå vad som sker.
Länk till ordlista på engelska för vanliga begrepp inom ML Machine Learning Ordlista
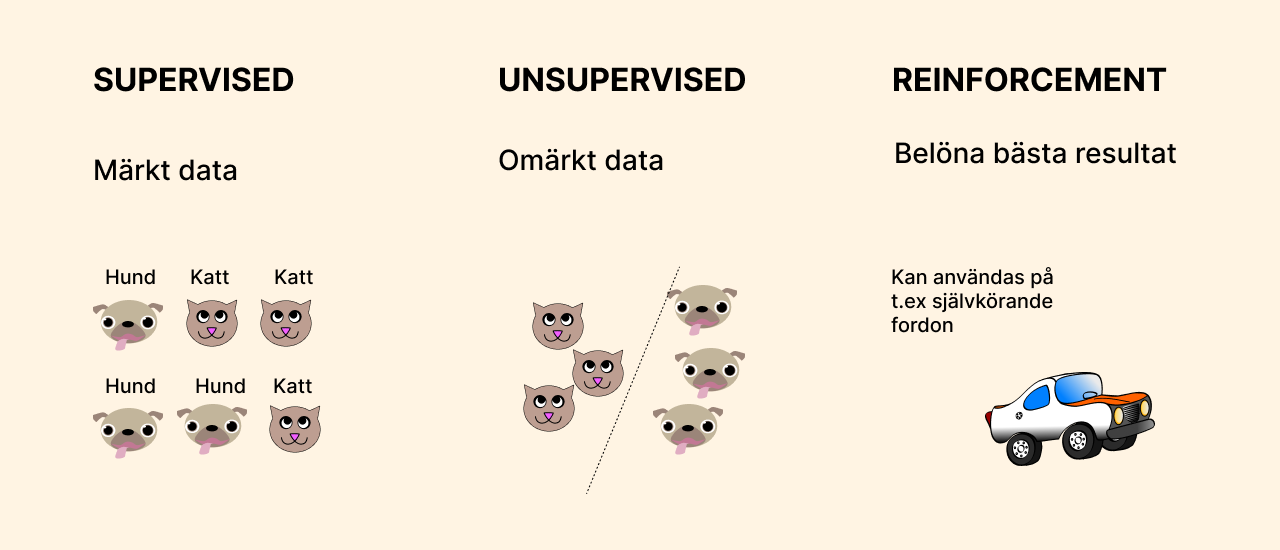
Supervised learning är en typ av maskininlärning där datamodeller tränas med hjälp av tillgång till kategoriserade data. Modellen lär sig att förutsäga resultatet för nya data baserat på de tidigare tränade data.
Om det man arbetar med är bilder så görs de om till en matris av siffror. Om det handlar om ljud så görs de först om till en bild (ett så kallat spectrogram) för att sen bli en matris av siffror. Från de siffrorna försöker datorn hitta specifika särdrag för varje kategori (kallas feature extraction). När modellen tränats ett antal gånger på träningsdata kan den förhoppningsvis klassificera ny osedd data. Supervised learning används ofta för att lösa problem som klassificering och regression. Regression ger inte en speciell klass utan en siffra (typ förväntad lön beroenda av var du bor, din ålder, utbildning mm).
Data som används delas upp i två delar, träningsdata och testdata.
Här matas data in helt utan märkning. Datorn får då försöka hitta särdrag och placera varje data i ett kluster med liknande data. När träningen är gjord kontrollerar datorn ny data och placerar den i det kluster som den bäst passar i. Vanlig användning är rekommendationer av varor/filmer/böcker på nätet. Unsupervised learning kan användas till klustering eller association. Klustering har ett antal klasser men utan angivna namn. Association fungerar så här: Om du köper korv och korvbröd kan du rekommenderas ketchup.
Här lär sig algoritmen genom att få positiv eller negativ feedback. Tänk ett självkörande fordon. Om det krockar får den negativ feedback. om den väjer för hinder får den positiv feedback.
I slutet av 2022 skedden en "explosion" av nya AI verktyg vilka kan generera text, bilder, musik mm. Anledningen till att det nu kommer så många AI verktyg är att det nu finns tillgång till mycket data, att datorer har blivit snabbare och kraftfullare, att många avancerade algoritmer har utvecklats och att det finns ett stort publikt intresse för AI. Det kan vara värt att fundera på vilka nackdelar den snabba utvecklingen kan medföra.
En av dessa verktyg, som imponerat mycket är ChatGPT vilket är en chatbot-teknologi utvecklad av OpenAI. Den är tränad med en avancerat maskininlärningsalgoritm vilket gör att den kan generera naturligt språk och svara på frågor på ett samtalslikt sätt. Superviced Learning och Reinforcement Learning användes för modellen.
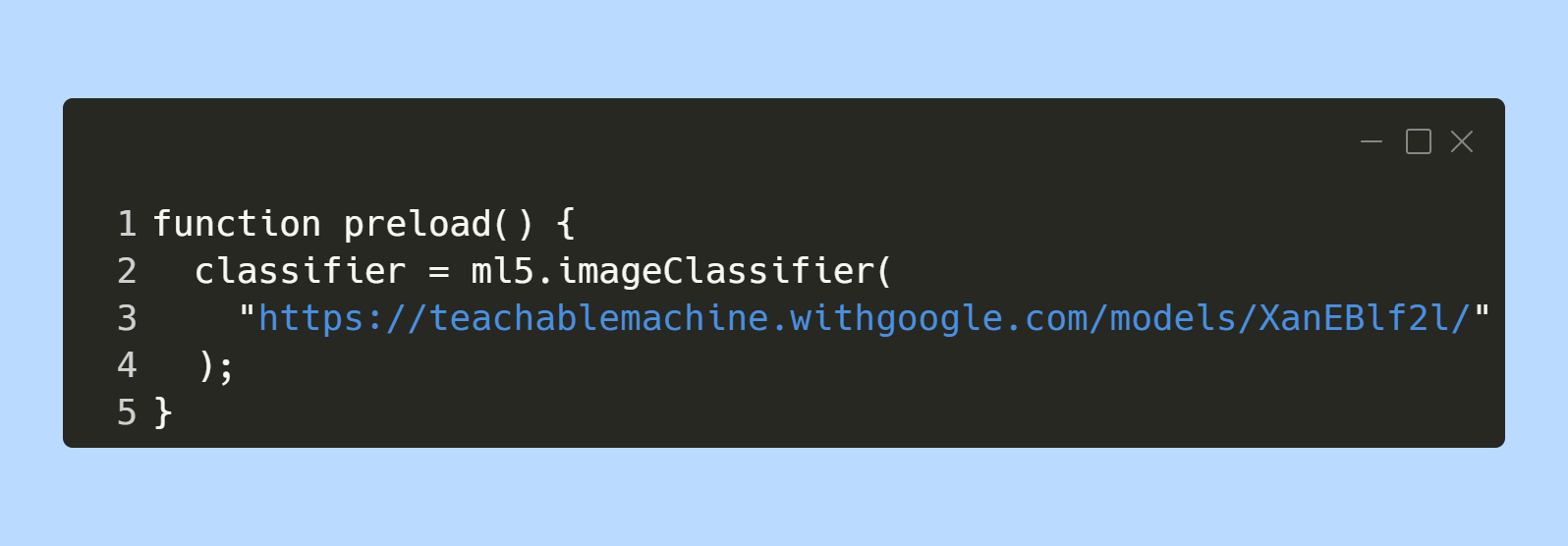
Med Teachable Machine kan man lätt testa att träna sin egen ML model. Modellen kan bestå av bilder, ljud eller kroppspositioner vilka kan skapas direkt genom datorns kamera/mikrofon.
Först samlar man data. Programmet har en massa algoritmer som lokaliserar särdrag i varje del av träningsdata. Därefter tränas modellen och man kan testa den. Sen kan man exportera modellen för att använda i andra program. Man kan också välja att få en länk till den för att kunna använda den online.
Teachable Machine gör klassificering med supervised machine learning. Genom att mata in sin data där man talar om vilken klass data tillhör lär sig datorn att hitta några speciella särdrag för att sen känna igen de olika klasserna på ny data som datorn tidigare inte sett.
ml5.js är ett projekt där man tagit fram ett JavaScript bibliotek vilket gör att man lätt kan
arbeta med Machine Learning direkt i browsern. ml5.js bygger på TensorFlow.js. ml5.js fungerar mycket bra med p5.js vilket är mitt
favoritverktyg när det gäller att lära sig programmera på ett enkelt och roligt sätt.
Se mer om p5.js .
Genom att använda ml5.js kan man också lägga in den modell man tränat i Teachable Machine i ett p5.js program och göra något kul med den.
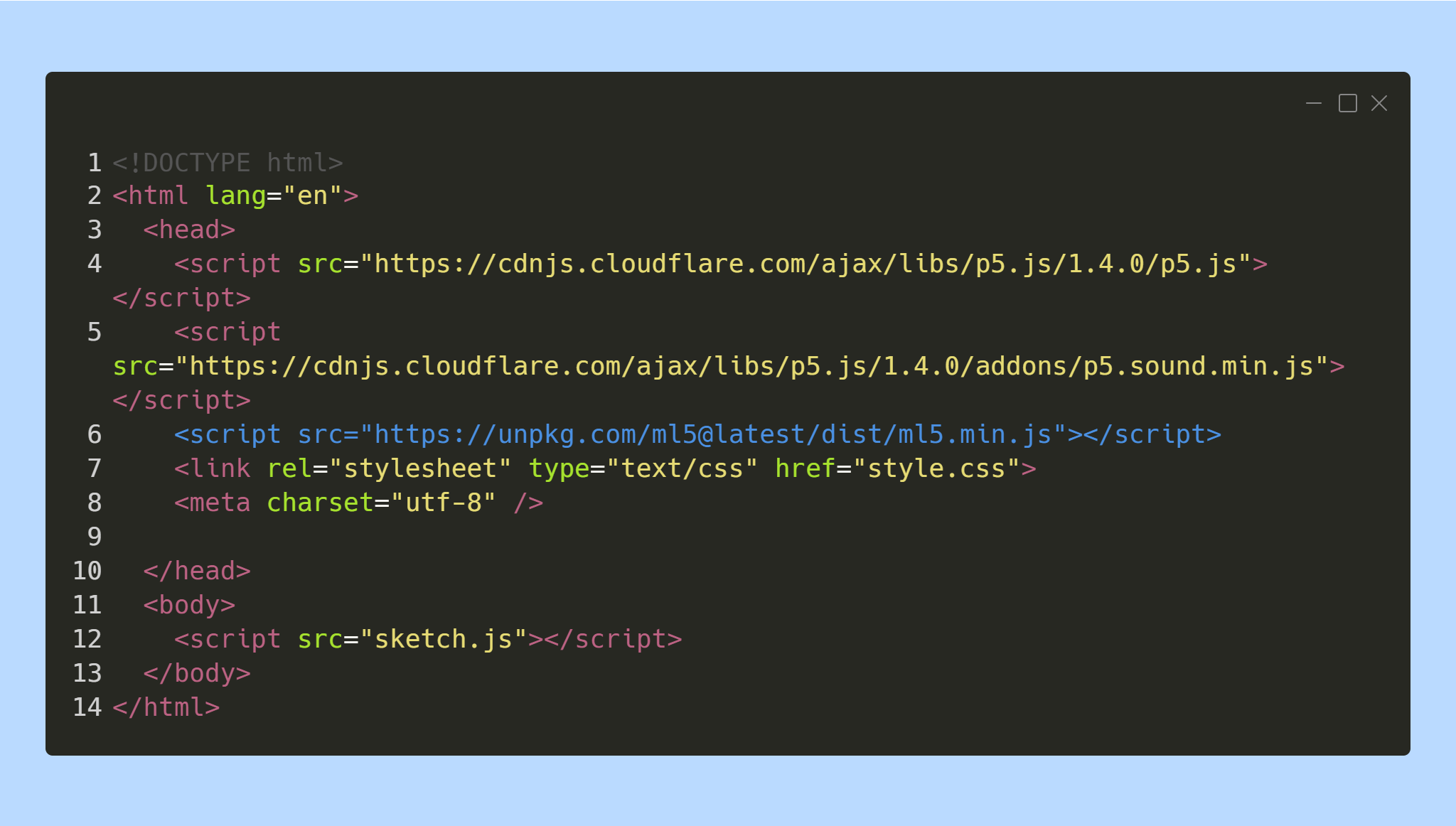
För att använda ml5.js i p5.js editor behöver en rad läggas till i index.html. Det som står på rad 6 är det som måste läggas till. Koden finns att kopiera från ml5 sidan Getting Started
Jag tränade en modell i Teachable Machine (TM) där jag höll upp färgat papper.
Den första klassen kallade jag "Left" och höll upp ett grönt papper och tog ca 50 bilder, den andra "Right" med orange papper.
Jag skapade också en klass med namnet "Nothing" där jag inte höll upp något papper alls.
När man namnger sina klasser är det viktigt att hålla koll på versaler och gemener.
Namnet måste stavas exakt lika när man sen använder dem i p5.js. Antal bilder i varje klass bör vara ungefär lika många.
Sen tränade jag modellen och kopierade länken till den.
Länk till den sketch jag sen gjorde i p5.js.
Jag använde även min modell till att styra ett Pong-spel.
Spelet går väldigt långsamt men det kan man ändra genom att änvra variablerna xSpeed och ySpeed i filen pong.js.
Troligtvis behöver man skapa sin egen modell i TM
för att det ska fungera bra.
Lägg in länken till din modell i p5.js sketchen istället för den kod som är blåmarkerad på bilden nedan.
MobileNet är en modell från TensorFlow som är tränad på ca 50 tusen bilder. Bilderna kommer från en databas som heter ImageNet. Där finns fler än 14 miljoner bilder indelade i olika klasser. Att själv samla sin data är väldigt tidskrävande och risken finns att den inte blir pålitlig då man behöver fundera över om "allt" är med eller om man kanske har missat att tänka på något. Du kan läsa vilka klasser som finns på data från ImageNet
Ett program i p5.js där jag använder MobileNet för att se vad modellen tror att jag visar upp framför kameran och med vilken säkerhet i % som modellen har för sitt val.
Transfer Learning fokuserar på att lagra kunskap som erhållits när man löser ett problem och tillämpar det på ett annat men relaterat problem. Här tar man alltså en modell som är tränad och använder de särdrag (features) som den kommit fram till och använder det för att träna annan data.
I p5.js har jag ett program där man använder den tekniken för att klassificera två olika saker (här mobiltelefon och apelsin). För att samla data håller man upp saker framför webkameran och klickar på knappen för den klass det ska tillhöra. Om klassificeringen inte kommer igång kan du behöva klicka i videorutan. Antal bilder man tar för varje klass påverkar resultatet (40 fungerar bra för mig). Att vinkla sakerna och flytta dem till olika positioner framför kameran kan också göra modellen bättre. När båda klasserna är klara klickar man på knappen "train" för att träna sin modell. När träningen är klar (det ser man genom att det i konsollen står "Training Completed") kan man testa att hålla upp sakerna igen och se om modellen fungerar. Text för modellens gissning står på skärmen.
Med KNN letar man efter de (K-antal) exempel i modellen som mest liknar den data vi matar in. Värdet på K anger man själv. NN står för Nearest Neighbors (närmaste grannar). Den klass som väljs är den som har högst representation av K-antal. I sketchen nedan är K 3 och ska illustrera hur KNN fungerar. Om man för musen över canvasen kan man se vilken av de fyra färgade klasserna som musens position ligger närmast.
KNN kräver inget träningssteg utan klassificerar löpande det man lägger in i modellen.
Mer om KNN från ml5.js. På länkad sida finns också The Coding Trains videor om KNN.
KNN sketch i p5.js
För att få det här programmet att fungera kan man hålla upp vänster hand så att den syns till vänster på videobilden och trycka
på tangentbordet l (för left) ett antal gånger. r (för right) för höger hand.
u (för up) för hand i övre delen av videobilden och d (för down) för nedre delen av videobilden.
Om klassificeringen inte kommer igång kan du behöva klicka i videorutan eller i canvasen.
I konsollen kan man se hur många gånger man klassificerat respektive position.
Efter att man klassificerat ett antal gånger av varje position
kan cirkeln på canvasen styras med de positionerna. Man kan naturligtsvis hålla upp vad man vill framför kameran men programmet är sen
kodat för att reagera på klasserna l, r, u och d. Det går att spara programmet när det är tränat men då det inte går att
ladda upp för stora filer till p5.js så går jag inte igenom det här. Om man vill lära mer och processen med att spara och ladda upp
sin modell rekommenderar jag filmer från The Coding Train vilka finns under länken till Mer om KNN från ml5.js ovan.

Object detection går ut på att upptäcka objekt i en bild. COCO står för Common Objects in Context och SSD står för Single Shot MultiBox Detection. Det betyder att modellen kan hitta fler objekt i varje bild. Det finns 90 klasser som modellen kan hitta. Länk till klasserna.
Ett program i p5.js där jag använder COCOSSD för att se vilka objekt som modellen ser att jag visar upp framför kameran. Modellen ritar ut en grön rektangel runt de objekt som den klassificerar.
Med ml5.js kan man använda
TensorFlow.js modell som heter SpeechCommands18w
vilket är en modell som klassificerar 18 ord. Att klassificera ord kallas också för keyword spotting och används bland annat av Alexa och Google Assistant.
Orden i SpeechCommands18w är:
talen "zero" till "nine", “up” och “down”, “left” och “right”, "go" och "stop" samt "yes" och "no"
Fördelen med att använda en färdig datamängd är att den då fungerar på de flesta röster.
Om man vill skapa en egen datamängd krävs många olika människors röster för att den ska bli bra.
I p5.js har jag skapat ett program där antal blobbar och blobbarnas rörelse påverkas av alla de olika nyckelorden.
I ett annat projekt som jag jobbat med har jag använt 5 nyckelord för att köra ett AI fordon med micro:bit (se under Projekt).

Med Teachable Machine kan man skapa egna modeller med något man själv säger. Igen används Transfer Learning.
Om man tränar modellen bara med sin egen röst kommer den troligtsvis inte att fungera på andras röster.
Som med all Machine Learning kräva STORA mängder data för att den modellen ska fungera på olika användare.
För att träna modellen i TM med ljud behövs de klasser som ska klassificeras OCH en klass med bakgrundsljud.
Varje ljudfil ska vara ca 1 sekund lång. Ljudfilerna görs sen ( i modellen) om till spectrogram.
Eftersom ett spectrogram är en bild av en visuell represenation av en
signals frekvens över tid så kan det användas som vilken bild som helst.
Om man har arbetat med Scratch från MIT så kan man under fliken "ljud" se en bild av ett ljud.
I programmet
(som syns som .gif nedan) har jag tränat "min hund" att reagera på att jag säger orden "happy och sad".
Eftersom jag tränat modellen bara med min röst så kommer inte modellen att fungera på andra röster.
Kom ihåg att du måste ändra i sketch.js filen till din egen modell om det ska fungera.
Lägg in länken till din modell i p5.js sketchen istället för den kod som är blåmarkerad på bilden nedan.
I MITT PROGRAM ÄR DET PÅ RAD 9 (inte 3).

Modellen identifierar 68 olika punkter (landmarks) i ansiktet och är ganska bra på att följa med när man rör sig.
Face Detection används ofta till olika appar, med filter, som Snapchat med flera.
I stället för punkter kan man rita ut "löjliga näsor", regnbågar, glasögon eller annat.

Landmarks på ansiktet är numrerade enligt bild nedan.

Ett program i p5.js där slumpmässiga smileys ritas ut på alla landmarks, när program startas.
Handpose är en maskininlärningsmodell som identifierar olika landmärken (landmarks) i handflata och fingrar.
Den kan upptäcka högst en hand åt gången och ger 21 punkter som beskriver viktiga platser på handflatan och fingrarna.
Det finns andra modeller som kan identifiera flera händer.
På gifen nedan kan man se de olika landmarksen som gröna punkter.

I programmet kan pekfingertoppen "röra runt" de hjärtan som ordet KomTek är uppbyggt av.
Genom att hålla upp handen framför webkameran upptäcks de olika landmarksen och
de små hjärt-smileysarna flyttar på sig när pekfingret är vid deras position och
återvänder till sin ursprungliga plats när pekfingertoppen inte är vid deras position.
Du kan ändra text på rad 20 i programmet där det står "KomTek". Viktigt är att din text står inom " ".
De olika landmarksen på handen benämns med tal enligt bild nedan. I programmet är det alltså landmark 8 som har påverkan på texten.
Under projekt finns en länk till ett projekt där jag använt HandPose för att ändra färg på en RGB lampa som är kopplad till ett micro:bit.
PoseNet identifierar 17 punkter (keypoints) på en människas kropp. Punkterna är numrerade från 0 till 16 (se bild nedan).
Olika modeller har olika antal punkter så det är värt att läsa på om modellen innan man börjar använda den.
MediaPipe är en annan, vanligen använd modell, som har 32 olika punkter.
Man kan använda en bild eller ett videoflöde via webkameran för att identifiera punkterna.
När modellen ser en bild så returnerar den x-koordinat, y-koordinat samt hur säker den är på sin uppskattning.
Vad kan det här användas till kan man ju undra.
Jag har bland annat använt den till att kunna byta slide på en PowerPoint genom att höja en hand.
Ett annat exempel är att imitera olika kroppspositioner som namnges och sen se om datorn kan gissa rätt.
Naturligtsvis är möjligheterna oändliga inom allt som kan styras och regleras. Bara brist på fantasi sätter gränser här.
Om du vill dyka djupare in hur det här fungerar rekommenderar jag att du tittar på YouTube filmer från Daniel Shiffman
När man raggar folk för att träna sin poseNet-modell kan det vara bra att informera dem om att deras bild INTE kommer att vara det som sparas i modellen. Bara de olika landmarksens position i olika bilder kommer att sparas. De kommer altså INTE att vara med på bild! De som person kommer inte att kunna identifieras (viktigt för GDPR).
Jag har skapat tre program som kan användas för att känna igen gester.
Jag använder dem för att känna igen 4 olika målgester från kända fotbollsspelare.
Först används poseNet för att samla in data sen tränas en modell i ett Artificiellt Neuralt Nätverk (Neural Network).
Neurala Nätverk försöker efterlikna hjärnans sätt att bearbeta information genom att använda en mängd neuroner.
Enklaste typen av Neuralt Nätverk består av ett input lager, ett hidden lager och ett output lager.
Om modellen har fler ett hidden lager kallas det för Deep Learning.
På gifen nedan kan man se ett Neuralt Nätverk där självkörande gröna bilar tränas. Som input används här 5 sensorer.
Data sänds fram och tillbaka genom nätverket för att bilarna ska lära sig att undvika alla hinder
såsom orangea bilar och vägbanans kanter.
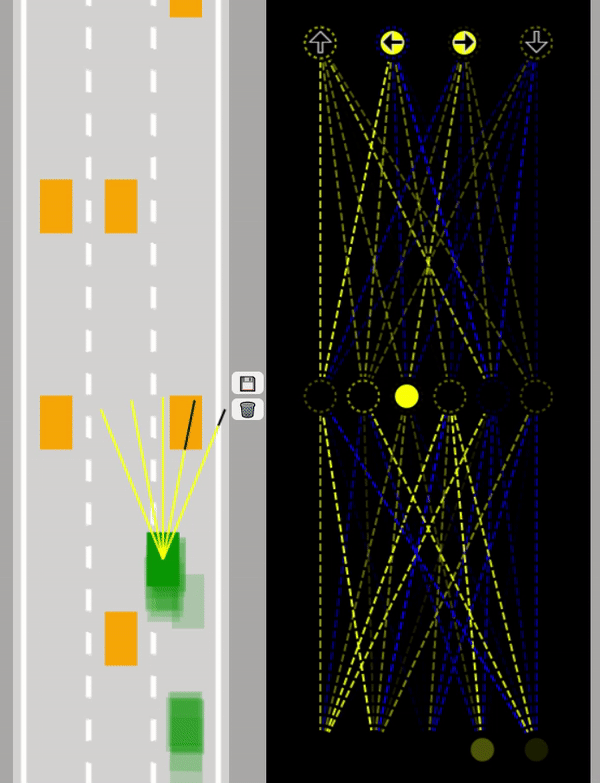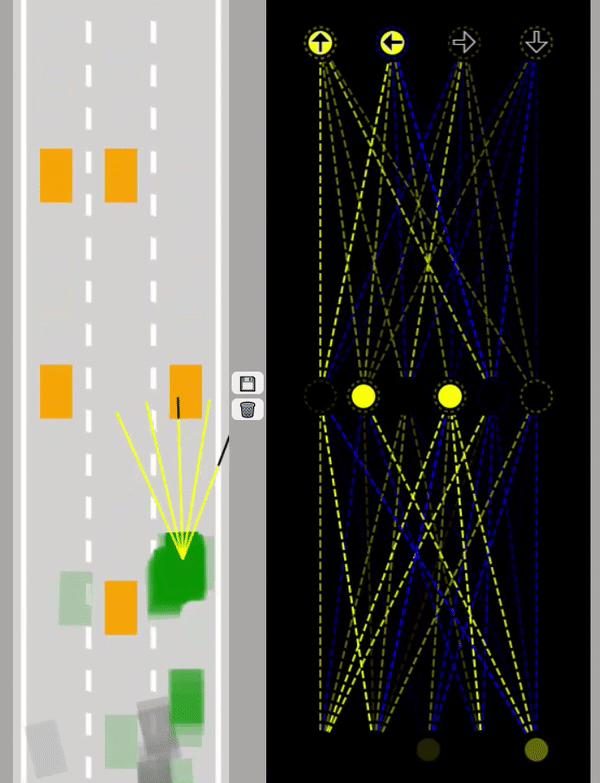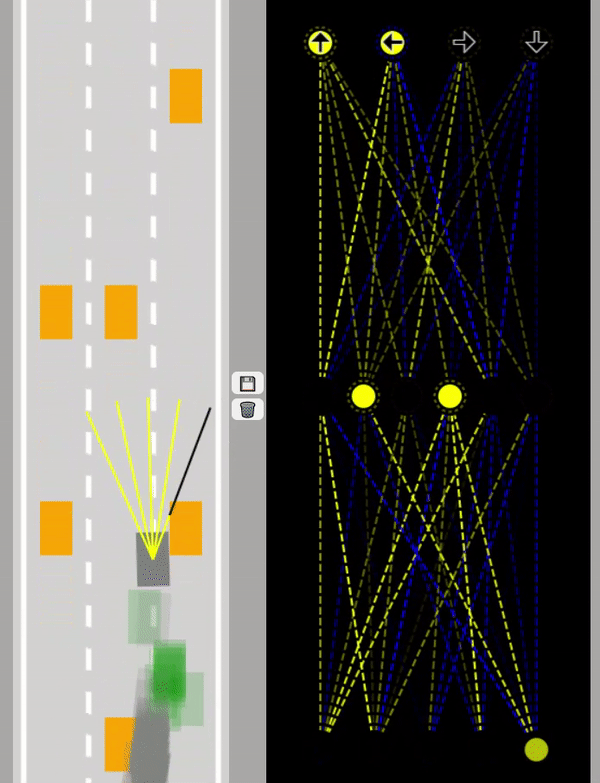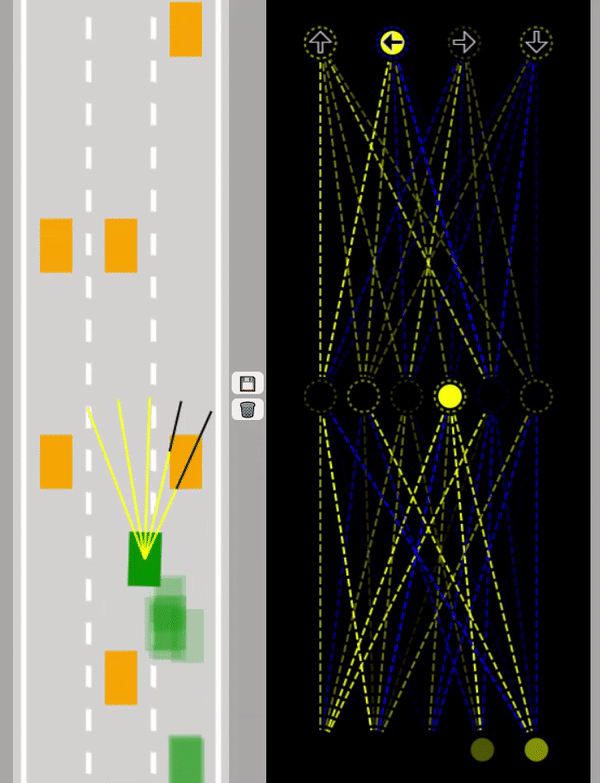
Lär mer om Neurala Nätverk på forskning.se
Program 1
samlar data genom att man klickar på en tangent, efter 10 sekunder
påbörjas insamling av data och det pågår i 10 sekunder. En person ställer sig framför webkameran och gör gesten för en målgest.
Det är bra att flytta lite på sig under de 10 sekunderna så att det blir lite variation på insamlad data.
Det samma görs för de andra 3 målgesterna. Låt sen några fler personer göra det samma. Tryck sen på tangenten s
för att ladda ner en fil med insamlad data till datorn.
Filen som laddas ner på datorn är en JSON (JavaScript Object Notation)
fil heter något datum och klockslag. Byt namn på den så den heter strike.json
I p5.js kan man bara ladda up filer som är mindre än 5MB så man kan inte samla hur mycket data som helst.
Att börja med 5 personer kan vara lämpligt.
De 4 tangenter jag valt är "q", "w", "e", "r".
Det går bra att välja vilka tangenter man vill men det är då viktigt att ändra i program 3.
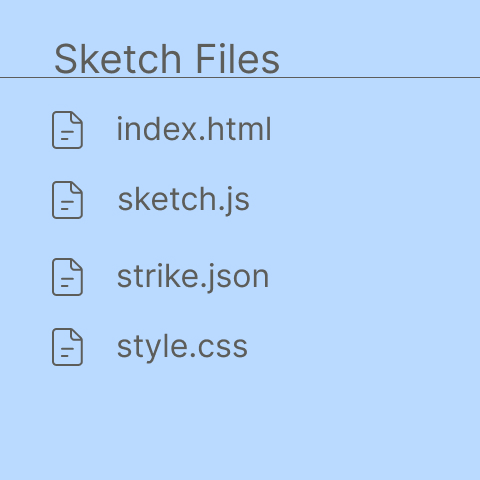
I Program 2 sker träningen av modellen. Ta bort filen strike.json som finns i mitt program och lägg dit den som du sparat på din dator. Trädstrukturen över filer ska se ut som på bilden nedan.
I koden sketch.js kan man se hur många inputs och outputs det är. 34 inputs är x och y värden för alla keypoints i poseNet modellen. 4 outputs är de olika målgesterna. task beskriver vad man vill använda sitt Neurala Nätverk till (här klassificering av gester). debug: true betyder att man vill se träningen på skärmen. All data kommer att köras igenom modellen 50 gånger. I koden bestäms det det där det står {epochs: 50}. När programmet körs kommer man att se på skärmen hur det tränas. Därefter laddas tre filer ner till datorn. De filerna ska användas i program 3.
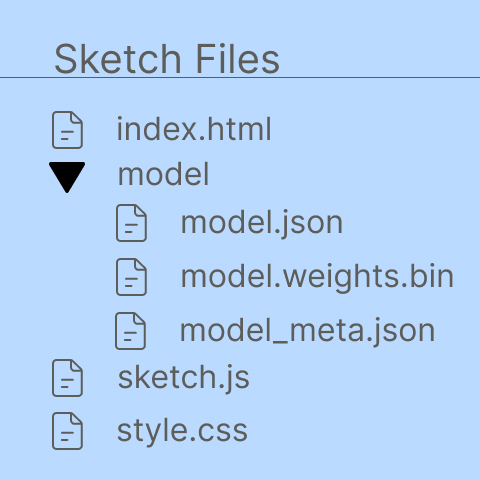
I Program 3 måste man skapa en ny folder med namnet model. I den foldern ska de tre filerna som laddades ner i program 2 läggas in. Namnet på filerna ska vara som det namn de fick när de laddades ner. Trädstrukturen över filer ska se ut som på bilden nedan.
Längst ner i filen sketch.js kan man se hur jag använt de fyra bokstäver som användes vid insamling av data. Jag skriver ut på skärmen vad modellen tror att jag gör för målgest. Namnet på fotbollsspelaren som jag försöker imitera skrivs ut på skärmen. Här behöver du ändra till det som gäller din modell.
Om du känner att du vill gå en kurs i AI så finns det en bra gratiskurs,
Elements of AI,
som skapats av Helsingfors Universitet i samverkan med Linköpings universitet och MinnaLearn.
Samma lärosäten har också skapat en kurs som heter Building AI där deltagarna använder Python som programmeringsspråk.
Som du kanske har märkt så finns det mesta information om, och redskap för, AI på engelska.
Om du vill bidra till att skapa dataset för röstigenkänning som innehåller röst från olika personer på olika språk så har
Mozilla (de som har browsern Firefox) ett fantastiskt initiativ, Common Voice,
där vi alla kan bidra till att göra framtidens teknikutveckling lite mer diversifierad.
Det bästa vore om folk i alla ålderskategorier kan vara representerade i datainsamlingar.
Data som samlas in via det vi gör på nätet blir
väldigt vinklad då det finns stora grupper som inte är aktiva på internet.
Datainsamling kan vara bra MEN vi måste se till att det är så "öppen data" som möjligt så vi alla kan avgöra om den är pålitlig.
Hör av dig via länken nedan om du undrar över något.